System Overview
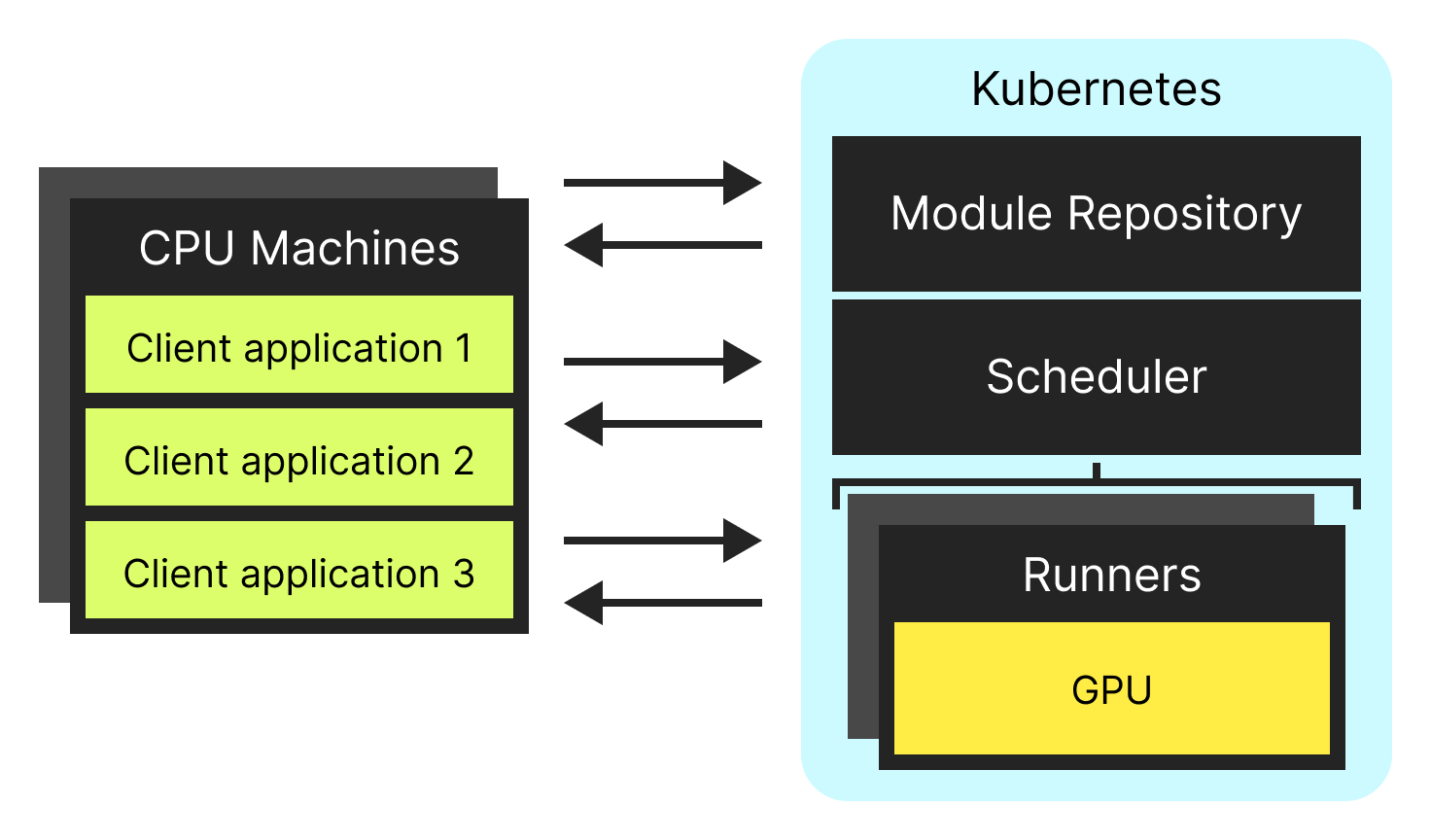
System components
The ExaDeploy system consists of a few components:
- Clients, who need access to virtualized GPUs. They have installed the Exafunction pip package, Bazel tarball, or other SDK.
- These correspond to your applications and will often be as simple to set up as switching a model run call to an ExaDeploy client API call.
- Your applications can run on VM instances, in a Kubernetes cluster, on your local machine within a VPN, or anywhere else that has connectivity to your ExaDeploy cluster.
- Server-side components, which exist inside your virtual private cloud (VPC).
- The scheduler, a Kubernetes service which routes clients to available GPUs and manages GPU cloud resources.
- The module repository, a Kubernetes service which stores code objects like ML frameworks and models.
- The runners, Kubernetes pods which own the GPUs and share the GPU execution time among their assigned clients.
Simple workflow
- A client connects to the module repository to register a model and/or ML framework to be used in future requests. Note that this only has to be done once per object and is persisted forever by the module repository.
- A client makes a request to the scheduler to perform a remote GPU computation.
- The scheduler will connect the client to an available runner and/or spin up more runners to handle the increased load.
- The runner executes the client's computation using the code objects it has fetched from the module repository and returns the result to the client.
Design considerations
The system is designed to be fault tolerant, with the following guarantees:
- At least 5,000 GPUs can be managed by a single scheduler.
- At least 25,000 clients can be managed by a single scheduler.
- The system can support network throughput on the order of 1 TB/s.
- If the scheduler or module repository are unavailable, existing clients are unaffected.
Questions?
Want to learn more about ExaDeploy or discuss how ExaDeploy could help accelerate your ML workloads? Please reach out on our community Slack!